I spent a very engaging couple of days with Boye & Company last week at the UK Digital Leadership and CMS Experts meetups. It’s a great community, expertly steered by Janus Boye and is always a highlight for me and chance to slow down, listen and reflect.
It
was great to hear about people’s challenges in diverse fields such as
banking, biotech, charity, education, CMS vendors (open source and
commercial) and agency side.
I really liked the talk about structured content and how important content strategy to a successful CMS strategy. An area that is often forgotten, with so much focus on web page layout rather than structured content that can be delivered in multiple ways.
AI
and agentic dominated a lot of the CMS Expert talk. I appreciated
hearing how others are using AI in their business. Clearly many are
finding success. And many are coming up with interesting ways to
understand it. Ethical points were raised too, from challenging the
inevitability of AI to sustainability and concerns on how juniors of the
future will learn. But it is clear AI is hugely dominant in the tech
space at present.
There
was talk that coding work is now replaced as a practice by AI and we’re
here to just solve customer problems now. I have thoughts about this
and will think more about it in the coming months. I believe AI is
better as an assistant than outsourcing your code writing to it
completely. Technical skills are important and I can’t see that
fundamentally changing (without huge risk). It’s important to check the
quality of AI solutions (which means you need to understand it).
Is this just a short-term win, or something that will work reliably in the long-term? And how successful is this where security, reliability, accessibility and other “enterprise” factors matter? Steven Pemberton is talking about this topic at the Boye Open Source CMS conference in October.
While
AI can feel overwhelming at times, there were lots of friendly people
to exchange ideas with. I came away with ideas on what to look at next.
I talked about CMS accessibility and digital sovereignty. A small few in a room of around 35 had heard of the Authoring Tool Accessibility Guidelines (ATAG), many had worked on accessibility reporting tools for CMS users, and I hope I sparked ideas and CMS vendors will start testing their CMSs against ATAG.
A lot of talk
about the pace of change, the importance of people, and the importance
of getting together to talk openly about all this! The tech may change,
but the underlying problems rarely do.
We work with larger public sector organisations who often require lists of third party dependencies we use on projects. I took at look at the different ways you can list all Composer dependencies in a PHP project.
This command lists all PHP dependencies in a project:
composer show
However, this displays as text. The compliance document I’m currently filling in is in Excel so ideally I need to copy this into Excel to send to the client.
You can also output your list of dependencies as JSON:
composer show --format=json
And then copy this into a tool such as Csvjson to convert to a CSV file.
I had to edit the JSON to convert to a flat CSV file, removing the root “installed” element. I edited the JSON from:
The JSON to CSV tool then downloads a clean CSV file which I can import into Excel and supply to my client!
Another useful command is:
composer licenses
That outputs the open source license used for each package. This also supports JSON output so can be converted to CSV in the same way.
CSV output seems a useful feature to me, so I suggested this on the Composer discussion board. If others agree, I’ll see if I can contribute this. Otherwise I may look at building a small Composer plugin.
Matt Mullenweg opened his WordCamp US 2024 Q&A presentation with “this may be one of my spiciest WordCamp presentations ever.” He went on to publicly attack WP Engine (a sponsor at Word Camp US) and the private equity firm behind them, Silver Lake. This left many attendees with a very negative ending to WordCamp.
Matt followed this up by posting on wordpress.org, the official website for the open source project WordPress, to continue his criticism of WP Engine. In his post Matt called WP Engine “a cancer to WordPress.”
This news post “WP Engine is not WordPress” will now appear on nearly every WordPress site in the world on the admin dashboard (official WordPress news channels have a very wide reach).
This is very strong criticism which to be honest seems uncalled for. And even if Matt has valid reasons there are better, more productive ways to address this. Using language like this feels very wrong to me, it’s poor leadership, and I can’t see how it makes the community stronger.
Matt’s core frustration appears to be how commercial companies use open source and don’t meaningfully contribute to it. He made a fair point saying commercial companies talking open source need to use real open source licenses and that what really makes open source is what he calls ecosystem thinking. He defined this as: Learn, evolve, nourish, teach.
He called out WP Engine for brand confusion, a lack of open source contributions to the WordPress project, and disabling core functionality on the WP Engine hosting platform.
A recent campaign to encourage more open source contribution called Five for the future has public declaration pages. Automattic pledges 3,786 hours a week, while WP Engine only commits 47 hours a week. Matt mentioned it was more like 40 and indeed the public contribution page has since been updated to this figure.
Comparing WP Engine to Automattic is clearly unreasonable. Automattic is the company run by Matt that essentially runs WordPress (strictly speaking it’s an open source project, but with heavy influence and direction from Automattic).
Other big WordPress tech companies such as Yoast contribute 150 hours a week, other hosting companies like BlueHost 53 hours and Siteground 42 hours.Yes, WP Engine could contribute more to core, but compared to others it’s not an awful record. And one I hope they can improve on.
The Five for the Future handbook states:
“It represents a goal to contribute 5% of your time or resources to the WordPress project, recognizing that any contribution, no matter the amount, is valuable.”
Shaming companies for not doing more goes against the project’s own values.
WP Engine is a big player in the WordPress space and isn’t perfect. It’s true buyouts and corporate investment can have a negative effect on good companies.
We’ve used the WP Engine hosting platform (both the Enterprise and normal hosting packages) and the restrictions of their setup can be frustrating. But it does work fairly well and our past experience of support has been good.
They purchased and now actively develop Advanced Content Fields (ACF), possibly the most essential plugin for professional WordPress development (it has an open source version). Interestingly I see WordPress is developing what may be a replacement for ACF with custom fields in the Block Editor.
Matt’s follow up blog post stated WP Engine disable revisions, a core part of WordPress, simply to make money. The storage mechanism for revisions is not great and high numbers of revisions can seriously affect performance. So limiting or disabling this is a fairly common approach.
There are lots of businesses using WordPress as the foundation for their business. If more people use WordPress, WordPress as a whole grows. Not everyone has to contribute to core to make a positive impact to the wider WordPress community. And if big businesses use WordPress, more people will use WordPress. It’s a virtuous cycle.
In the Q&A one person accused Matt of “punching down” and said “what seems like vendettas are demotivating. With stalled market share we need to promote new people coming into WordPress. WordPress started with people hacking on it. Not negativity.”
I think a stalled market share is natural. At 43% WordPress already commands a huge share of the web. But the web thrives on different people doing different things, and I don’t think it would be healthy for the web for one platform to dominate.
If WordPress wants to grow perhaps they could focus on working with the wider PHP ecosystem to encourage developers to use WordPress for more use cases. For example, supporting Composer the excellent package manager for PHP.
Later in his talk, Matt said “The idea we’re creating is bigger than any one person.” Does that include him?
EDIT (26 Sept 2024): Ryan McCue wrote a good post on why it’s important for the whole WordPress community that WP Engine succeed in this unfair legal battle with Automattic/WordPress.
I’ve had a really relaxing Christmas break with the family this year, only opening my laptop to read my friend’s advent murder mystery. I sit here drinking a Christmas beer (a Belgium beer called Père Noël by De Ranke) writing a short post summing up 2023 and my hopes for this year. In a minute I’ll get back to that murder mystery and try to work out whodunnit!
Work
2023 was a challenging year for many digital agencies. With the economic slowdown continuing many of my peers at other digital shops reported difficulties winning new work. We experienced similar challenges throughout a lot of 2023, but I’m glad things picked up in the autumn and we finished the year with 3 new charity clients – something I’m very proud of (both for the effort my team put into the sales work and the fact we’re increasing our roster of charity clients).
We hired local strategic digital marketing firm Sookio to undertake a positioning review for Studio 24, which really helped focus how we talk about ourselves. So far we’ve updated the Studio 24 homepage and have a new tagline “Building a better web, together.” We have a whole new website in the plans which we will launch later in 2024!
During 2023 I worked with the excellent business coach Susie McFarland. Our monthly sessions (and a few in-person workshops) really helped dig into different areas of running an agency and how we can improve it. I found this really useful and we have a ton of really valuable, actionable stuff to help improve the agency in 2024.
In July I joined the BIMA Sustainability Council, it’s an area I think is really important for all businesses to tackle and I hope to help move things forward within the BIMA community. Around the same time I started looking at what it would take for Studio 24 to become B Corp accredited, something I am keen to achieve in the next year.
Late September / early October was a particularly busy time for me. Across 3 weeks I hosted a Boye & Co Digital Leadership meeting in London, attended the HE Connect conference in Liverpool (my first time in this amazing city), and travelled to Barcelona to talk about the W3C redesign and accessibility at DotAll, the Craft CMS conference. This was an amazing experience, I took along 2 of my work colleagues, met many lovely folk in the Craft CMS community, and after the conference enjoyed an extended trip with the family exploring Barcelona.
In December I travelled with another colleague to Brussels for SymfonyCon, met up with a friend and took the opportunity to meet up with our client, W3C, who were also attending. Although remote work can be great I really enjoy seeing people in person!
Looking back on last year’s post we did start having quarterly in-person company days last year, which I think is really needed now we’re a remote first company. Among many client website launches I was very proud to see the new W3C website redesign launch live in June which we received a string of awards for, culminating in the Gaddys award which Emma travelled to sunny San Francisco to accept the award!
Family and friends
My family and I saw My Neighbour Totoro at the Barbican in January, it was simply amazing. The way they used puppetry to mimic the animation of the film was beautiful, the music was incredible – the band suspended up in the trees – composed by Joe Hisaishi, who worked on the original film. They have another run on now so if you can see it I’d recommend it. Other theatre trips included the brilliant Accidental Death of an Anarchist at the Hammersmith Lyric. Daniel Rigby was a sparkling ball of energy as the Maniac. And Dear England at the National Theatre. I went to this with friends and took Bill along, who really enjoyed it. It was nice to see such a mixed audience of young and old watching a play about football!
As well as Barcelona and Brussels for work, I travelled to Porto with friends in January. It was an amazing trip, and like typical Englishmen the 4 of us happened to be out walking with our umbrellas just when the flash floods hit Porto – flooding the streets and causing a lot of damage. We managed to walk for 5 minutes in the old town before, utterly soaked and up against torrents of water, we holed up in a cafe and waited until the rain passed with hot chocolate!
Family trips this year were in the UK, with a big family meet-up in Bath (my first time there), a trip to Southwold and Latitude Festival, and trips to Oxford, Lewes and Norfolk.
We were lucky enough to get tickets to Wimbledon this year and I took Bill along. Was brill to see world class tennis players compete, including seeing Carlos Alcaraz in the practise courts.
One of the highlights of the Cambridge Film Festival this year was watching documentaries Senna and Maradonna in the presence of filmmaker Asif Kapadia. Asif was at the festival for a couple of days and was very generous in his Q&As (often expanding on really interesting points linked to the original question) and talking to the Youth Lab team about how to get into filmmaking.
What does 2024 hold?
I want to spend more time relaxing and enjoying time with family and friends. I hope to have an extended holiday this summer travelling across Europe with my son Bill (by train we hope), once he’s finished his GCSEs.
I want to see more theatre. I am off to Soho Theatre tomorrow and we have a trip planned to Stratford-upon-Avon (which I’ve never visited). The brilliant Matthew Baynton (of Ghosts fame) is playing Bottom in A Midsummer Night’s Dream which has to be seen!
I’d like to learn something new. Not really sure what, but probably something creative. I shall await serendipity!
I have a few work resolutions for 2024. One is helping improve how we use documentation at Studio 24. Reading the GitLab remote handbook it’s clear written documentation is key to working successfully remote first.
I’d like to attend more in-person events where I get the chance to collaborate with people from different backgrounds. The Boye & Co events are good for this, they bring together people across client-side, government, academia, and industry. Cross collaboration is something I really value and I feel always brings out good results.
And I’d like to create more. Although I lead an agency I’ve always loved making things with technology, so hope I get the opportunity to build something useful this year.
That’s me for now, I hope you have a most excellent 2024!
It’s been a while since I posted an end of year review, so thought I’d have a go!
Work
It’s been a busy year at Studio 24 and I was really ready for a break by Christmas. It feels like we’re finally coming out of the pandemic years properly. We had our 11th Studio Day at the wonderful Fitzwilliam Museum (a client) with everyone in attendance for the first time since the pandemic. As ever, it is wonderful to see people in person. We’ve managed to create a successful format for these all-staff days. Some games to warm people up, a little bit of business stuff, lightning talks from anyone on any topic (always really creative and fun), and one interactive session where we work on something to improve the agency. We currently have these twice a year and I hope to increase the frequency in 2023.
We worked on a wide range of projects in 2022. Some of the most fulfilling was our work with CBM, the global disability charity. Earlier in 2022, we launched a Ukrainian language version of the Humanitarian Hands-on Tool (HHoT) website in response to the war in Ukraine. This was a fairly short turnaround but felt really important. The HHoT website is focussed on sharing information on how to provide inclusive humanitarian aid.
Later in the year we launched the Inclusive Participation Toolbox which is all about including persons with disabilities in development and humanitarian programs. We’re really passionate about working with charities and not-for-profit and hope to do more of this type of work in 2023.
In May, our long-time client Crossrail launched the Elizabeth Line. We’ve been working with them for over 13 years so it was amazing to see the new London Underground line be available for public use. Though it also marks the end of our relationship as Crossrail shuts down and everything is handed over to TfL. It’s been a great experience and a valuable stepping stone to public sector work.
We also started a bunch of new things at Studio 24. Volunteer days (a few of us helped the Rowan Forest School), Hack Days (the dev team get together to experiment and try new things), we had a work experience student for the first time since the pandemic, and Nicki launched our accessible front-end starter kit Apollo which we now use on all client projects (and is available to anyone as an open source project). We’ve already seen the impact as new staff join and can onboard to our front-end practices quickly.
Earlier in 2022 also saw us finish officially working on the W3C redesign project. It’s been a massive effort over the past 2 years with amazing work across the Studio 24 team and at W3C. After working remotely with W3C for 2 years I finally met some of the core team in person in the south of France in early September, which was amazing! W3C are very busy with the transition to non-profit status. We continue to keep in touch to help support W3C with the final stages of finishing the Beta site before it launches publicly (hopefully in early 2023!).
I attended a bunch of interesting events last year including Web Summer Camp, dConstruct, Boye & Co Digital Leadership Day in Cambridge, and Higher Education Connect (I talked at 2 of these events). It was nice to get back to in-person gatherings where it’s so much easier to meet new people and share experiences.
A few team members moved on to new jobs (always sad to see people go, but I wish them the best). We hired a new Front-End Developer, Miro, and advertised for 2 new roles in December. We successfully hired for the first role, Web Developer, just before the Christmas break and are still looking for a PHP Developer to join the team. It was amazing how many people applied for the Web Developer role, with 215 applications in just over a month! We use the excellent software Homerun to help manage applications, it certainly made processing large numbers of applicants far easier.
Personal development
For the first time I’ve hired a business coach to help me improve the business (and myself), so far this is going really well. It’s good to have someone external to talk to who has a deep understanding of running agencies. Over the past few years I’ve talked to more people about agency life and there certainly seems to be more people willing to share experiences than there used to be when I started.
Public speaking
I’ve always been fairly reluctant to do public speaking, but also keen to share knowledge and get out there more. It’s something I’d like to make more time for. This year we seem to have had a lot more success with public speaking at Studio 24.
I spoke about the W3C redesign project at Web Summer Camp in September, an amazing conference run by friendly agency NetGen on the coast in beautiful Croatia. I also spoke about writing for accessibility at HE Connect in Manchester in October.
Marie, our Front-End Team Lead, spoke about W3C, Craft and accessibility at Craft CMS’s conference dotCMS in New York City at the end of September.
We’ll be looking for more places to share our knowledge in 2023.
The arts
The 41st Cambridge Film Festival, of which I’m a trustee, ran in October half-term, which was great fun. It’s still a really challenging time for charities and cinema, but it felt like a step closer to pre-pandemic audiences and was a really well run festival this year. Highlights included comedy The Banshees of Inisherin, set around the start of the Irish Civil War, Corsage, the modern and brilliantly acted retelling of Empress Elizabeth “Sisi” of Austria, and the hilariously dark Triangle of Sadness. My favourite film of the festival was Sinjar, a superb Catalan film about three women whose lives have been affected by ISIS. It was a well told story with some superb performances and natural realism.
Fitzwilliam Museum had a superb exhibition on called Defaced, a very modern exhibition on money and protest and how it’s been used by society. Some great artifacts such as forged British notes created by prisoners of war in Germany and artwork created with worthless banknotes (due to hyperinflation). I attended the opening and we had a curator-led tour as part of our Studio Day which was fascinating. If you get a chance it’s on until 8th Jan.
I saw the brilliant Best of Enemies at Nöel Coward Theatre in December. I wasn’t aware of the political TV battle of wits between liberal Gore Vidal and right-wing William F. Buckley before. Zachary Quinto and David Harewood give superb performances and the production is very modern and engaging.
As ever, the Panto at Cambridge Arts Theatre, another of our clients, was a great evening out. Panto is so much fun and I’ve really got back into it as an adult.
A couple of book highlights. I’m usually a fiction fan but I really enjoyed Bob Mortimer’s hilarious autobiography And Away and David Attenborough’s important A Life on Our Planet about the threat to our planet through biodiversity loss and climate change.
In November the family all attended a book talk by Randall Munroe, of XKCD fame, talking about his new book What If 2. The talk was at the Department of Chemistry in Cambridge and was hosted by Adam Rutherford. Randall was pretty laid back and told lots of funny stories about his journey writing What If.
Travel
One trip with friends to Luxembourg in February where we also ventured into Germany to visit Trier, the oldest city in Germany (founded by the Romans). It was a fun trip, though one of my friends sadly couldn’t join since he contracted Covid just before travelling. In Germany we encountered some quite strict Covid rules, we had to present our Covid pass every time we entered a bar or restaurant. Sensible precautions, but it feels like such a different world already only 10 months on.
I travelled to Nice and Sophia Antopolis, France in early Sept to visit W3C en route to speaking at Web Summer Camp in Šibenik, Croatia. It was my first time in Croatia and it is an incredibly beautiful country. I’ll certainly be coming back.
Family trips this year have been in the UK, visiting family and a long weekend to Leicester to visit the National Space Centre and the King Richard III visitor centre. Both were really interesting, we all love anything to do with space and it was good to see the story of how King Richard III was found in a council car park (we saw the dramatisation later in the year in the film The Lost King).
I plan to start 2023 with My Neighbour Totoro at the Barbican with the family and a trip with friends to Porto, Portugal. Should be a good year ahead…
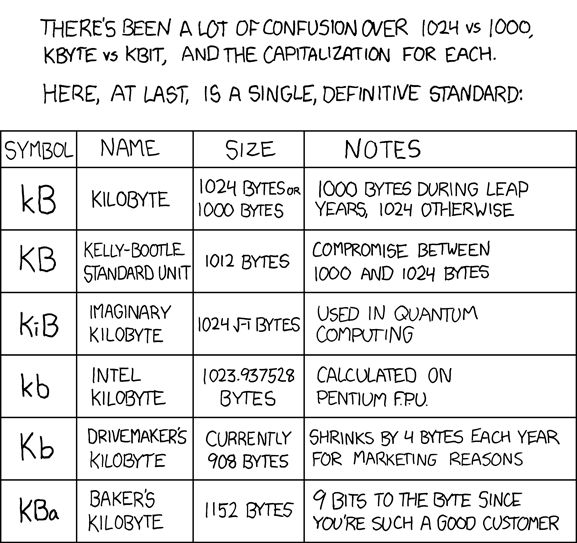
I helped my 14-year old son with his homework today and there was a question about how to convert from Kilobytes (KB) to Megabytes (MB). My instinct was to tell him to divide by 1024 (the more technically accurate version of a KB) but we both decided the answer they wanted was 1,000.
In my work creating websites and web applications we sometimes report on filesizes, usually in human-readable formats such as reporting on the filesize in MB. For example, a document listing may include the filesize to give the user an idea of how long a download may take.
So this made me think about how we calculate human-readable versions of filesizes on websites. In the past we tend to divide bytes by (1024 * 1024) to get to MB. Now I wasn’t so sure. So I had a bit of a read around.
Binary and decimal units
Historically computers have always used binary units, since that’s how computers work. At their simplest level everything is either a 1 or a 0.
Traditionally a kilobyte is 1024 bytes, a megabyte is 1024 kilobytes, a gigabyte 1024 megabytes, and so on. This is called base 2 (or binary) since these numbers are all a power of 2 (1024 = 210 bytes).
As computers became more mainstream people naturally assumed a kilobyte meant 1000 bytes, a megabyte 1000 kilobytes, since base 10 (or decimal) is what we’re used to as humans.
So we currently have two ways to describe a kilobyte: decimal (1,000 bytes) or binary (1,024 bytes).
Messy real world definitions
There seems to be a lot of confusion in computing with developers often using the “more accurate” binary unit to calculate file sizes and others using the decimal unit.
In the early days of the web most computers used binary units to report filesizes. This has changed over time.
It turns out hard drive manufacturers refer to storage sizes using the decimal format. So a 100 MB hard drive is actually 100 * 1000 KB (rather than 100 * 1024 KB). This results in a smaller storage space than if you used the binary unit to calculate storage size (e.g. 1 GB = 1,000,000,000 bytes in decimal or 1,073,741,824 bytes in binary, this is around 7% smaller). Good for sales, less good for the consumer.
There’s even a Wikipedia page on the confusion this has created. Interestingly this notes that the US legal system has decided “1 GB = 1,000,000,000 bytes (the decimal definition) rather than the binary definition.”
There are also standards. IEC 80000-13, published in 2008, defines a kibibyte (or KiB) as 1024 bytes and a kilobyte (KB) as 1000 bytes.
According to the Institute of Electrical and Electronics Engineers (IEEE) the decimal format should be used as standard unless noted in a case-by-case basis (see Historical Context on this NIST reference page). This is also known as SI, The International System of Units, which defines the prefix killo as 1,000.
So technically you should write KiB if you mean 1024 bytes. But it turns out very few people do this, and everyone just sticks to kilobytes or KB whether they mean decimal or binary.
So today we’re still stuck with some people using KB = 1024 bytes and some people using KB = 1000 bytes. Yay!
However, clearly most people don’t care. And storage sizes are so large now most people don’t really notice the differences. Unless you’re a computer or web engineer who has to do calculations on this sort of thing.
What do modern operating systems use?
Well, here’s where it gets interesting.
In my early days of web development (which started around 1999) I used a Windows PC, these days I use a Mac. While hard drives advertised their size in decimal units, Windows itself reported filesizes in binary. So in practical terms a 1 GB hard drive actually had less space for file storage on it (around 953 MB available space). I remember that annoying me!
In the early days of Macs and smartphones they also reported filesizes in binary units. So it made sense that most people used binary units to report filesizes on web apps.
From 2009 Mac switched to reporting file sizes in decimal (with Mac OS X Snow Leopard, presumably in response to the IEC standard). This didn’t happen until 2017 for iOS and Android.
Today Ubuntu Linux, Mac OS, iOS and Android use decimal for file storage sizes. Windows, as far as I’m aware, still uses binary units. However, to spice things up Microsoft’s cloud office service 365 uses decimal units when referring to cloud storage size!
So today if you have a file which is 500,000 bytes in size this would report as 488 KB (binary) on Windows and 500 KB (decimal) on Macs, Ubuntu Linux and modern smartphones.
What works for users?
Which is right? To be honest, I don’t think that matters. What’s more important is which makes more sense for your users.
Most web development resources still tell you to use a binary units to convert between file storage sizes (e.g. bytes to KB).
But as you can see, almost everyone else uses decimal units in the real world (except for Windows OS – but even Microsoft uses decimal for their cross-platform 365 service).
When building web applications it’s always best to do what is best for your users. So now, most of the time I think it makes more sense to report filesizes using decimal units rather than binary (so 1,000 bytes = 1 KB). Which is the opposite to what I thought before I started writing this post!
Just to make things fun, other measurements which use kilobytes actually do use binary units consistently, computer memory (or RAM) being the obvious example. As far as I know every system out there uses binary units for measuring memory!
At Studio 24 we work with a lot of government and public sector clients, who are understandly keen to comply with GDPR and are therefore careful about where data is sent and stored.
There is a strong preference to use services that store all data within UK or the European Economic Area (EEA).
This is an issue for many SaaS products since most of them store data in the US or Canada. While there is the EU-US Privacy Shield agreement this has become uncertain after Brexit.
Where possible, we aim to use EAA or UK hosted data for public sector digital services. Where that’s not possible we can use non-EU hosted data for services, but we need to justify this with our clients.
Two tools we currently use for error reporting and monitoring are Bugsnag and Usersnap. After my review I discovered Bugsnag is hosted in the US, though Usersnap is hosted in Europe. A summary of my research on data storage locations is below.
In addition I’ve also added notes on where you can strip indentifying user data from external data storage. This can be helpful for data privacy.
Hosted in EAA
Usersnap
Data hosted on AWS in Europe (Germany or Ireland). GDPR docs are a bit sparse but you can request more details via email. It’s not really possible to strip data via Usersnap due to how it works (on demand screenshot tool rather than automated monitoring).